

Improving the Developer Experience: Shifting from DevOps to Platform Engineering at SilverRail

23/11/2022
Written by Ariel Richtman
As I blow out the candle on my one-year-at-SilverRail cake, I thought now would be a good time to reflect on one of the major projects I’ve been heading up as a Platform Engineer.
Entering the business with a fresh pair of eyes gave me tonnes of ideas as to how to level up SilverRail’s continuous delivery workflow and empower the team with the tools they need to ship quality code at a speed that works for them.
To paraphrase: I wanted to improve the developer experience by supporting a swamped DevOps team with a semi-managed platform to help engineers move fast and not break things — something our QA team is already nailing.
So, join me as I outline some of the motivations for this transition, explain the challenges we faced along the way, and describe the solutions that are making it easier than ever for our global team to create industry-leading software that changes the way people move and helps build a greener planet.
Why Transition from DevOps to Platform?
The truth is, no technology function is perfect. If you look hard enough, you’ll eventually turn a stone that reveals a strain or inefficiency that requires attention. Almost all software teams endure the challenges of building new and exciting solutions using outdated tools — the important thing is to dedicate time to upgrading those tools and avoid burying your team in the day-to-day.
In the case of SilverRail, I’m pleased to report that I was pleasantly surprised by the state of play when I first joined. However, as anyone who knows me will testify, I’m not the type to sit by the sidelines when I spot something that could be improved.
Specifically, I was struck by the pressure placed on SilverRail’s DevOps team to operate and maintain our continuous integration/continuous delivery (CI/CD) system. For a company that is consistently exercising the muscles that produce working software, there was a general feeling among engineers that, in order to improve the developer experience, we needed to reduce the reliance on DevOps to avoid bottlenecking our delivery workflow.
Given SilverRail’s mission to make rail easy, it only seemed fair that we apply the same philosophy to our internal teams. My job is to identify those inefficiencies and develop helpful solutions that mean we’re all singing the same tune and opening our laptops each morning feeling empowered.
So, how could we turn to technology to relieve our DevOps teams and support our engineers without compromising on quality?
Our answer came in the form of Platform Engineering using a self-hosted Gitlab platform on AWS Elastic Compute Cloud (EC2). However, before we talk specs and implementation, let’s first dig deeper into some of the reasons why our existing CI/CD system was falling short of the mark.
Challenges of DevOps-Managed CI/CD Systems
Besides the more obvious productivity challenges of centralising our CI/CD function around a single team, one of the more nuanced consequences involved ring-fencing specialist knowledge for things like Amazon Machine Image (AMI) generation and containerisation which were kept in a silo by DevOps.
Excluding ‘external’ engineers from the CI/CD function meant they didn’t have the same exposure to many of the emerging tools that are now core to our tech stack. This lack of familiarisation was something we wanted to address as it’s our job to enrich engineers with new skills and ensure they’re always moving forward. Every day should be a school day at SilverRail.
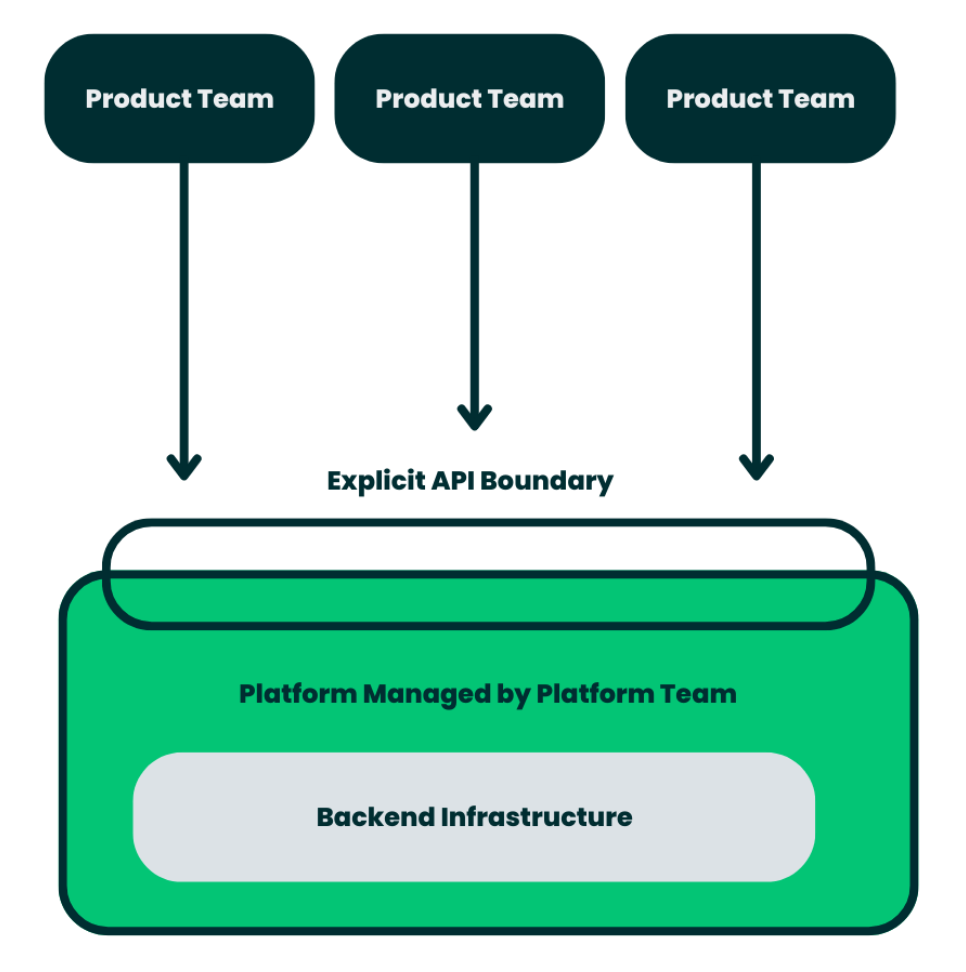
Gatekeeping the solution from our product teams would have presented new bottlenecks and dependencies that hinder CI/CD. We needed an approach that offers flexibility and gives engineers visibility of what the heck is going on.
Another challenge of centralising our CI/CD function was the separation between our build and run operations. Despite the collaborative intent of ‘Dev meet Ops, Ops meet Dev’, I felt the existing system was doing anything but federating the relationship.
To add fuel to the fire, we were still using an old Jenkins system for a handful of legacy jobs where our licence limit meant we could only run ten parallel jobs at once. As is often the case with legacy set-ups, the system vendor had all but abandoned the project — meaning parts of our workflow were slower than others and multiple jobs would occasionally foul with each other.
Everything considered, I was confident that it was time for a change. We needed a new experience, a new way of supporting continuous delivery, and as was now clearer than ever, we needed a new platform.
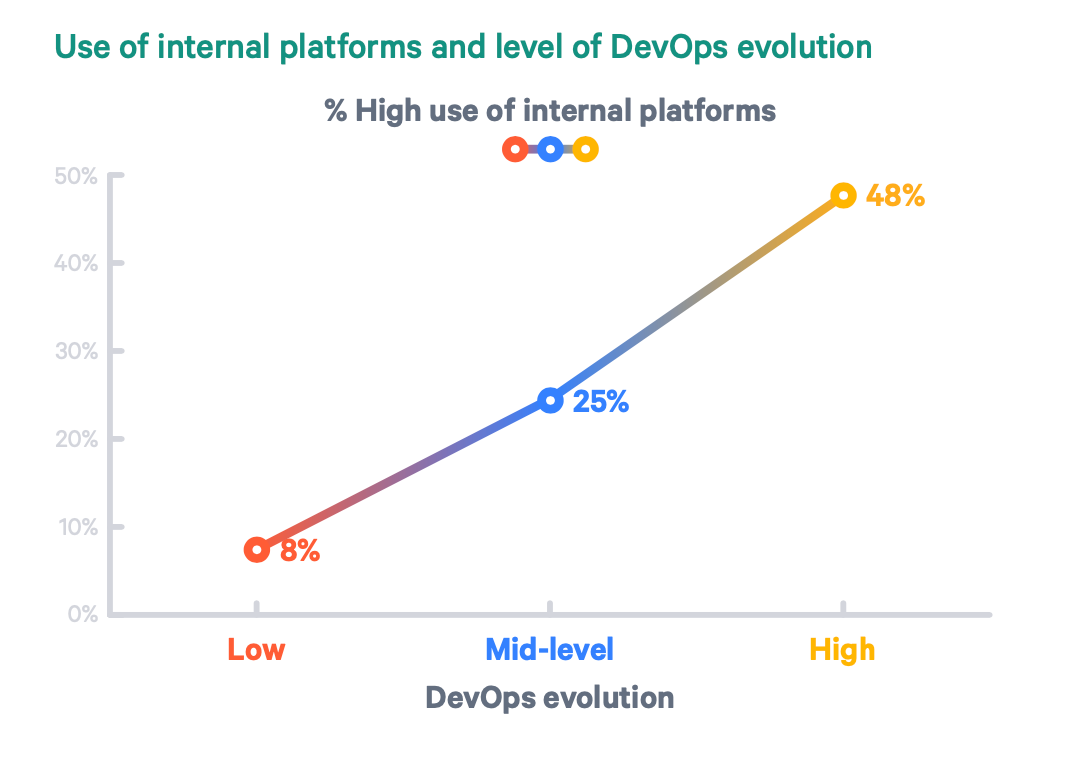
Now there’s a positive correlation if I’ve ever seen one. My job is to support the developer experience so that this trend line leaves the top-right corner of the page (source).
Developing An Approach
Now that we had a better idea of what problems we were looking to solve, we decided that the best path forward was to build solutions that worked out of the box on day one. The goal was to empower our engineers with something that works for over 90% of their use cases so they’re not drowning in complexity or trying to reinvent the wheel every time they sit down at their laptops.
We also needed something that engineers could self-service and directly contribute to with new features and fixes so that they’re not dependent on another team if something goes wrong. This way, our engineers are empowered to manage their own workflow and aren’t reliant on other teams to triage fixes.
The mission was to let our engineers ship early, often, and with less effort.
While this all sounds good in theory, I was well aware that the main challenge would be to get buy-in from our engineers and to position the platform as something they actually want to use. I needed to make it desirable. After all, I’m asking them to take on my view of the world and make changes to their current workflow.
At this point, I turned to the trusty words of James Clear (author of Atomic Habits) to identify some key principles that would shape the platform development:
- It had to be easy
- It had to be the default
- It had to add value to the individual and the team
- It had to be quick
Delivering The Solution
In not-so-simple terms, my task was to bridge the gap between software and hardware by setting out self-service deployments of proven combinations of cloud services to host software. Yes, that is a mouthful.
Essentially we wanted to build a platform that provides golden patterns in a self-service model to the software engineering function. In this specific context, the platform we’re building is for CI/CD.
In terms of specs, we went with GitLab self-hosted on EC2. While I did consider a fully-managed option, we eventually landed on a hybrid approach as we felt a straight SaaS platform wouldn’t have given us the flexibility or autonomy we needed. Outsourcing the platform would have been great from a resourcing point of view but we needed the agility and control of self-administration to manage specific runners and avoid the latency and control issues that come with many SaaS platforms.
Using GitLab, we set about building the best experience we could for a software engineer. This involved a combination of an out-of-the-box ‘just-works’ configuration, training, reference implementations, templates, and libraries. We also added a pinch of meta tooling for good measure to give an added layer of customisation and control.

Top-level config to make jobs “Just Work”
Configuring The Platform
Once the application was up-and-running, the next job was to make sure it was all configured correctly to avoid creating new CI/CD bottlenecks.
Specifically, I’d anticipated that authentication could present a significant upfront barrier to developer experiences. As a workaround, we pre-configured the application to automatically provide credentials to most of our common services for all running jobs. This means no more ‘docker login’ every time you start a job — you simply hit the API or service you need and it works securely.
Using a similar mechanism, we also pre-configured the environment variables for all jobs with sane defaults that can be overridden when required.
Another part of this configuration process involved tweaking the platform to make small jobs as ergonomic and hassle-free as possible. From suppressing progress bars to avoiding verbose output or informing build tools that they’re operating in a non-interactive environment, these subtle tweaks all contribute towards a smoother developer experience that supports CI/CD.
For workloads, we opted for a ‘just-go’ approach to runners — deploying compute resources at the root level of the application. This meant anyone in the team could harness the platform’s full potential and run jobs without dependencies on others. Importantly, this also allows users to run jobs in their private groups, avoid shadow infrastructure, and minimise disputes over utilisation.
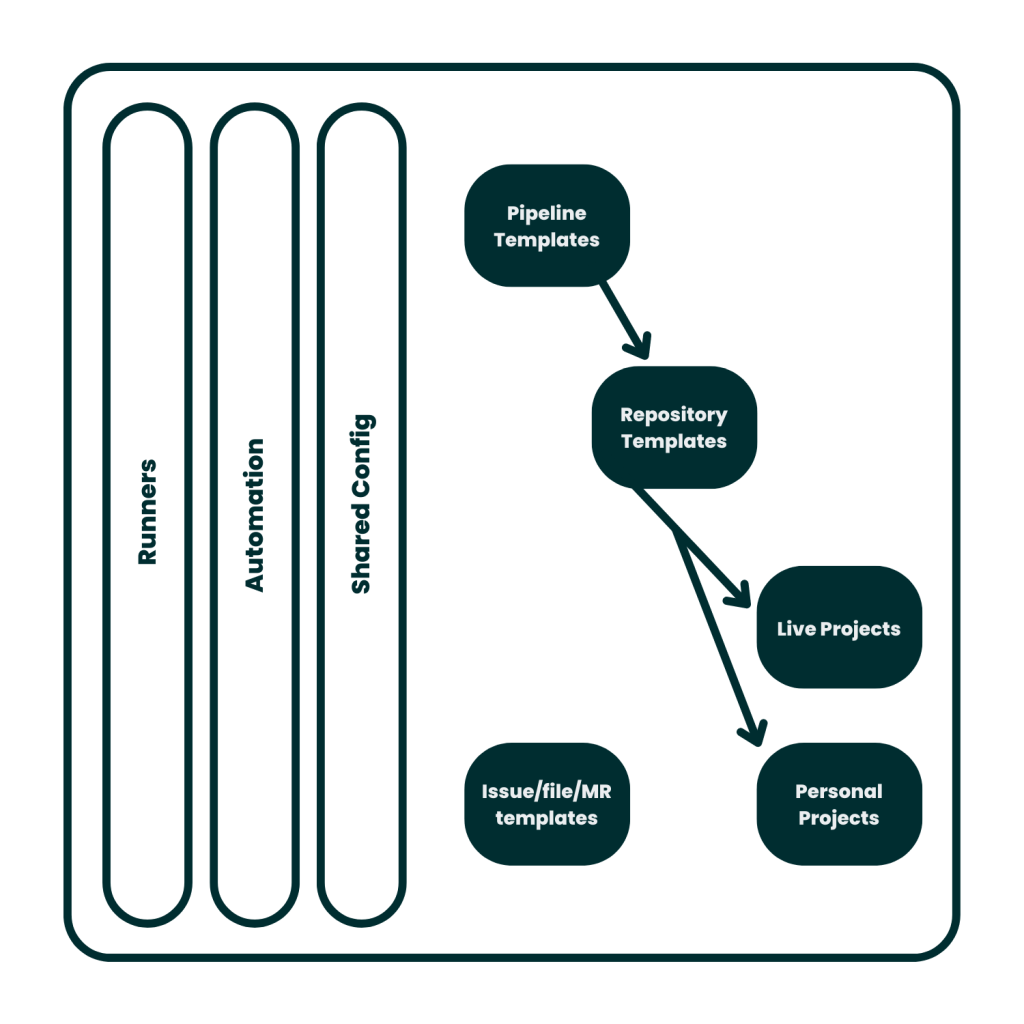
A snapshot of SilverRail’s new-and-improved CI/CD workflow
Deploying the Platform
Now that we had the infrastructure in place and the configuration was flexible, it was time to put the theory to the test by encouraging the team to start using it.
As part of this onboarding process, we opted to deploy Marge Bot — a tool that allows engineers to simply assign their merge requests to a bot and automatically rebase and merge the changes (provided the CI tests pass). This helps to reduce friction when team members are adopting the application for the first time.
We also deployed WhiteSource’s Renovate Bot to scan repositories for updatable dependencies and suggest fixes using branch and merge requests. The motivation here was to reduce the amount of time spent on managing stale dependencies, provide a natural prompt to re-run pipelines and deployments, and contribute to security posture.
As a fail-safe, we kept both Marge Bot and Renovate Bot as opt-in features for the initial deployment to reduce any unexpected shocks like disappearing merge requests or finding oneself buried in hundreds of them.
We also developed a library of CI/CD jobs that could be used by engineers and went one step further by creating reference implementations that used the jobs — meaning anyone can inspect a working model. Both the libraries and implementations are internally available for inspection and contribution (see below).

Fully functional pipeline using the libraries for abstraction and convenience.
Communicating the Platform
From a people perspective, the final piece of the puzzle was to help the team get the most out of the platform.
This involved authoring internal documentation that not only covered the what and the how, but also explained the why. Why were we making the transition and who stands to benefit? We provided best-practice tips and tricks, a tutorial section, and delivered our own in-house tiered training for engineers to dive as deep (or shallow) as they liked into the platform.
The finishing touch to encourage uptake was providing implementation support to the early adopters. This familiarised a vanguard of developers who could seed enthusiasm and support onboarding efforts across our global developer teams.
Ship Early, Often, and With Less Effort at SilverRail
If you’re an engineer looking to combine your passion for tech with a sense of purpose, SilverRail could be the place for you.
Our transition from DevOps to Platform is just one example of what happens when a company listens to its employees and isn’t afraid to shake things up to optimise developer experiences.
To learn more about how we’re breaking the mould to support continuous delivery without compromising on quality, check out this article from our Senior Software QA Engineer, Gignesh Patel. He explores how our quality-orientated approach provides engineers with the confidence they need to build groundbreaking products.
If you like what you see, check out our open positions to see how you could be part of a global team that’s harnessing technology to make rail easy, change the way people move, and build a greener planet.
